

The Complete Guide to Encoding Categorical Features
Your ready reference for encoding any categorical data




Photo by Lukas Blazek on Unsplash
Table of contents
- Introduction
- Why do we need to Encode Categorical Features?
- Types of Categorical Features
- Challenges with Categorical Features
- What we will cover today?
- Label Encoding
- One-Hot Encoding or Dummy Encoding
- Binary Encoding
- Ordinal Encoding
- Frequency Encoding or Count Encoding
- Target Encoding or Mean Encoding
- Feature Hashing or Hashing Trick
- Concluding thoughts
Introduction
In the world of data analysis and machine learning, data comes in all shapes and sizes.
Categorical data is one of the most common forms of data that you will encounter in your data science journey. It represents discrete, distinct categories or labels, and it's an essential part of many real-world datasets.
In this article, we will discuss the best techniques to encode categorical features in great detail along with their code implementations. We will also discuss the best practices and how to select the right encoding technique.
The objective of this article is to serve as a ready reference for whenever you wish to encode categorical features in your dataset.
Why do we need to Encode Categorical Features?
Many machine learning algorithms require numerical input.
Categorical data, being non-numeric, needs to be transformed into a numerical format for these algorithms to work.
Types of Categorical Features
Categorical features are encoded based on the their types and functions. They can be broadly divided into two categories: Nominal and Ordinal.
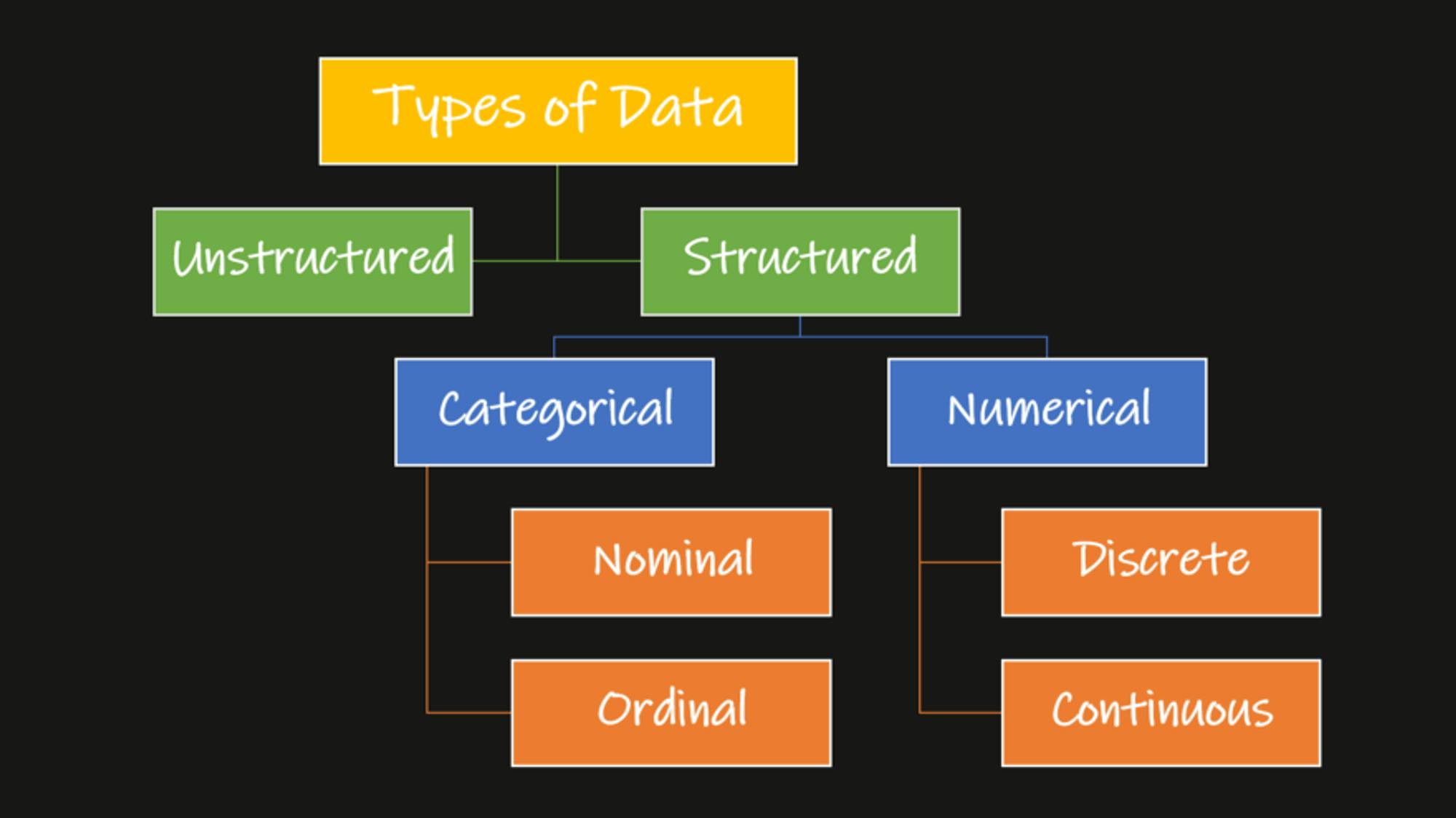
Nominal Categorical Features
Nominal features are those where the categories have no inherent order or ranking.
For example, the colors of cars (red, blue, green) are nominal because there's no natural order to them.
Ordinal Categorical Features
Ordinal features are those where the categories have a meaningful order or rank.
Think of education levels (high school, bachelor's, master's, Ph.D.), for which there is a clear ranking.
Learn more about categorical data & other types of data from the below resource.
Challenges with Categorical Features
Categorical data brings its own set of challenges when it comes to data analysis and machine learning. Here are some key challenges:
Numerical Requirement: Many machine learning algorithms require numerical input. Categorical data, being non-numeric, needs to be transformed into a numerical format for these algorithms to work.
Curse of Dimensionality: One-hot encoding, a common technique, can lead to a high number of new columns (dimensions) in your dataset, which can increase computational complexity and storage requirements.
Multicollinearity: In one-hot encoding, the newly created binary columns can be correlated, which can be problematic for some models that assume independence between features.
Data Sparsity: When one-hot encoding is used, it can lead to sparse matrices, where most of the entries are zero. This can be memory-inefficient and affect model performance.
What we will cover today?
The encoding techniques we will discuss today are listed below:
Label Encoding
One-hot Encoding
Binary Encoding
Ordinal Encoding
Frequency Encoding or Count Encoding
Target Encoding or Mean Encoding
Feature Hashing or Hashing Trick
Let us discuss each in detail.
Label Encoding
Label encoding is one of the fundamental techniques for converting categorical data into a numerical format. It assigns numbers in increasing order to the labels in an ordinal categorical feature.
It is a simple yet effective method that assigns a unique integer to each category in a feature.
How it works?
Imagine a feature 'Size' that has the following labels: 'Small', 'Medium', and 'Large'. This is an ordinal categorical feature as there is an inherent order in the labels.
We can encode these labels as following:
Small → 0
Medium → 1
Large → 2
Code Implementation
Let us look at the code implementation for Label Encoding.
# necessary imports
from sklearn.preprocessing import LabelEncoder
# Sample data
data = ["Small", "Medium", "Large", "Medium", "Small"]
print(data) # Output: ['Red', 'Green', 'Blue', 'Red', 'Green']
# Initialize the label encoder
label_encoder = LabelEncoder()
# Fit and transform the data
encoded_data = label_encoder.fit_transform(data)
print(encoded_data) # Output: [2, 1, 0, 2, 1]
When to Use Label Encoding?
Label encoding is a suitable choice for:
Ordinal data or features with a clear and meaningful order.
Not increasing dimensionality in the dataset.
One-Hot Encoding or Dummy Encoding
One-hot encoding, also popularly known as dummy encoding, is a widely used technique for converting categorical data into a numerical format.
It's particularly suitable for nominal categorical features, where the categories have no inherent order or ranking.
How it works?
One-hot encoding transforms each label (or category) in a categorical feature into a binary column.
Each binary column corresponds to a specific category and indicates the presence (1) or absence (0) of that category in the original feature.
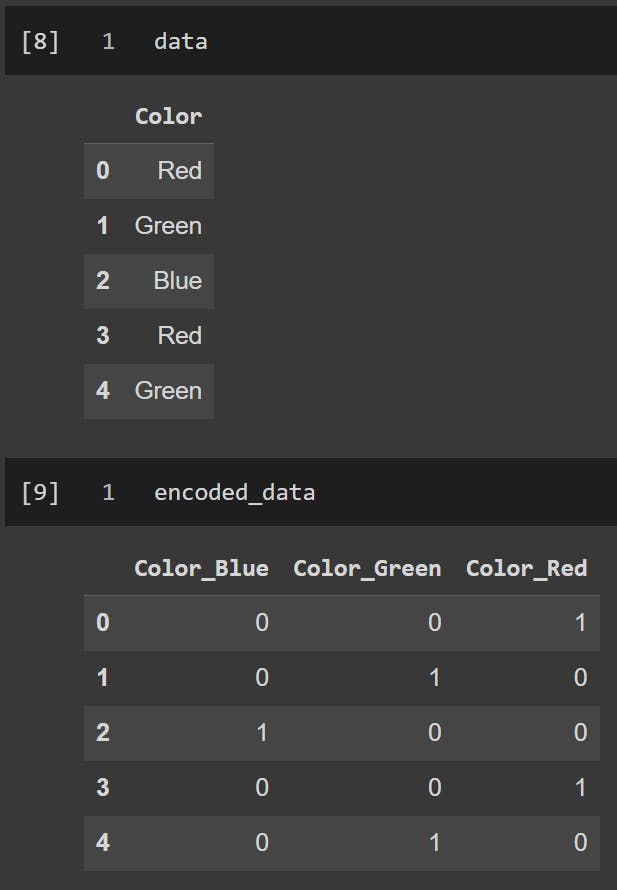
For example, consider a categorical feature "Color" with three labels: "Red," "Green," and "Blue." One-hot encoding would create three binary columns like this:
"Red" → [1, 0, 0]
"Green" → [0, 1, 0]
"Blue" → [0, 0, 1]
Code Implementation
Let us look at the code implementation for One-Hot Encoding.
# necessary imports
import pandas as pd
# Sample data
data = pd.DataFrame({'Color': ['Red', 'Green', 'Blue', 'Red', 'Green']})
# Perform one-hot encoding
encoded_data = pd.get_dummies(data, columns=['Color'])
The output will look like below:
Advantages of One-Hot Encoding
The primary advantage of one-hot encoding is that it maintains the distinctiveness of labels and prevents any unintended ordinality.
Each label becomes a separate feature, and the presence or absence of a category is explicitly represented.
When to Use?
One-hot encoding is an appropriate choice when:
Dealing with nominal data with no meaningful order among labels.
Maintaining the distinction between categories (or labels) is crucial, and no ordinality must be introduced.
It handles missing values the absence of a category results in all zeros in the one-hot encoded columns.
Challenges with one-hot encoding
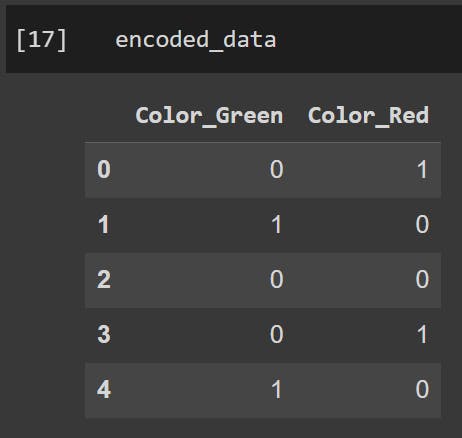
Dummy Variable Trap 💡
Be aware of the "dummy variable trap," where multicollinearity can occur if one column can be predicted from the others.
To avoid this, you can safely drop one of the one-hot encoded columns, reducing the dimensionality by one. You can declare the drop_first=True in the get_dummies function as shown below.
import pandas as pd
# Sample data
data = pd.DataFrame({'Color': ['Red', 'Green', 'Blue', 'Red', 'Green']})
# Perform one-hot encoding
encoded_data = pd.get_dummies(data, columns=['Color'], drop_first=True)
Output:
Curse of Dimensionality
One-hot encoding can lead to a high number of new columns (dimensions) in your dataset, which can increase computational complexity and storage requirements.
Multicollinearity
In one-hot encoding, the newly created binary columns can be correlated, which can be problematic for some models that assume independence between features.
Data Sparsity
When one-hot encoding is used, it can lead to sparse matrices, where most of the entries are zero. This can be memory-inefficient and affect model performance.
Binary Encoding
Binary encoding is a versatile technique for encoding categorical features, especially when dealing with high-cardinality data.
It combines the benefits of one-hot and label encoding while reducing dimensionality.
How it works?
Binary encoding works by converting each category into binary code and representing it as a sequence of binary digits (0s and 1s).
Each binary digit is then placed in a separate column, effectively creating a set of binary columns for each category.
The encoding process is as follows:
Assign a unique integer to each category, similar to label encoding.
Convert the integer to binary code.
Create a set of binary columns to represent the binary code.
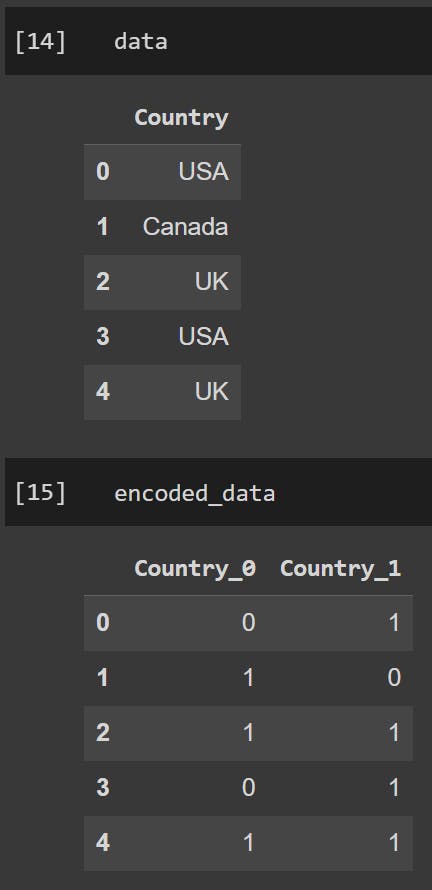
For example, consider a categorical feature "Country" with categories "USA," "Canada," and "UK."
Binary encoding would involve assigning unique integers to each country (e.g., "USA" -> 1, "Canada" -> 2, "UK" -> 3) and then converting these integers to binary code. The binary digits (0s and 1s) are then placed in separate binary columns:
"USA" → 1 → 001 → [0, 0, 1]
"Canada" → 2 → 010 → [0, 1, 0]
"UK" → 3 → 100 → [1, 0, 0]
Code Implementation
Let us go through an example in Python.
# necessary imports
import category_encoders as ce
import pandas as pd
# Sample data
data = pd.DataFrame({'Country': ['USA', 'Canada', 'UK', 'USA', 'UK']})
# Initialize the binary encoder
encoder = ce.BinaryEncoder(cols=['Country'])
# Fit and transform the data
encoded_data = encoder.fit_transform(data)
The output is below:
Advantages
It combines the advantages of both one-hot encoding and label encoding, efficiently converting categorical data into a binary format.
It is memory efficient and overcomes the curse of dimensionality.
Finally, it is easy to implement and interpret.
When to Use?
Binary encoding is a suitable choice when:
Dealing with high-cardinality categorical features (features with a large number of unique categories).
You want to reduce the dimensionality compared to one-hot encoding, especially for features with many unique categories.
Ordinal Encoding
As the name suggests, Ordinal Encoding encodes the categories in an ordinal feature by mapping it to integer values in ascending order of rank.
How it Works?
The process of ordinal encoding involves mapping each category to a unique integer, typically based on their order or rank.
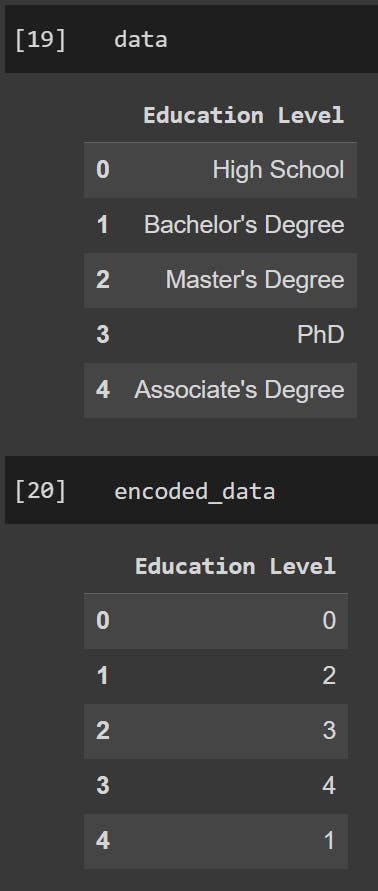
Consider an ordinal feature "Education Level" with categories: "High School," "Associate's Degree," "Bachelor's Degree," "Master's Degree," and "PhD".
Ordinal encoding will assign integer values as follows:
"High School" → 0
"Associate's Degree" → 1
"Bachelor's Degree" → 2
"Master's Degree" → 3
"PhD" → 4
These integer values reflect the ordinal relationship between the education levels.
Code Implementation
Here's how we implement Ordinal Encoding in Python.
# necessary imports
import category_encoders as ce
import pandas as pd
# Sample data
data = pd.DataFrame({"Education Level": ["High School", "Bachelor's Degree", "Master's Degree", "PhD", "Associate's Degree"]})
# Define the ordinal encoding mapping
education_mapping = {
'High School': 0,
"Associate's Degree": 1,
"Bachelor's Degree": 2,
"Master's Degree": 3,
'PhD': 4
}
# Perform ordinal encoding
encoder = ce.OrdinalEncoder(mapping=[{'col': 'Education Level', 'mapping': education_mapping}])
encoded_data = encoder.fit_transform(data)
Output:
Advantages
It captures and preserves the ordinal relationships between categories, which can be valuable for certain types of analyses.
It reduces the dimensionality of the dataset compared to one-hot encoding.
It provides a numerical representation of the data, making it suitable for many machine learning algorithms.
When to Use Ordinal Encoding
Ordinal encoding is an appropriate choice when:
Dealing with categorical features that exhibit a clear and meaningful order or ranking.
Preserving the ordinal relationship among categories is essential for your analysis or model.
You want to convert the data into a numerical format while maintaining the inherent order of the categories.
Frequency Encoding or Count Encoding
Frequency encoding, also known as count encoding, is a technique that encodes categorical features based on the frequency of each category in the dataset.
This method assigns each category a numerical value representing how often it occurs. It's a straightforward approach that can be effective in certain scenarios.
Categories that appear more frequently receive higher values, while less common categories receive lower values. This provides a numerical representation of the categories based on their prevalence.
How it works?
The process involves mapping each category to its frequency or count within the dataset.
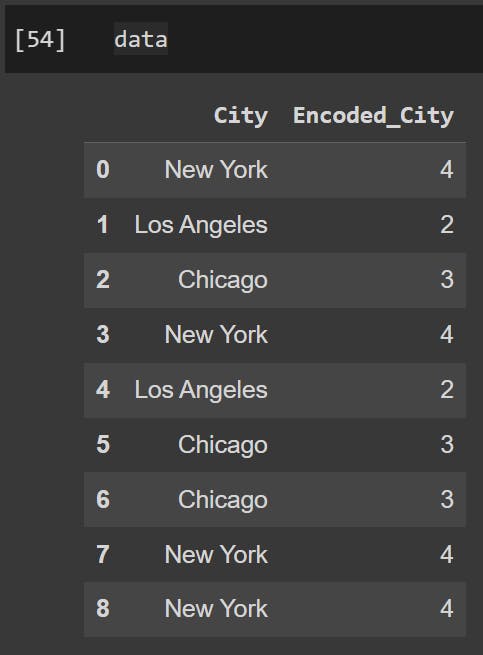
Consider a categorical feature "City" with categories "New York," "Los Angeles," "Chicago," and "San Francisco." If "New York" appears 50 times, "Los Angeles" 30 times, "Chicago" 20 times, and "San Francisco" 10 times, frequency encoding will assign values as follows:
"New York" → 50
"Los Angeles" → 30
"Chicago" → 20
"San Francisco" → 10
💡 NOTE
Frequency or Count Encoding is specially effective where the frequency of categories in a feature has a significant impact.
It should not be applied to ordinal categorical features.
Code Implementation
The implementation here is pretty straightforward.
# imports
import pandas as pd
# Sample data
data = pd.DataFrame({'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Los Angeles', 'Chicago', 'Chicago', 'New York', 'New York']})
# frequency encoding
frequency_encoding = data['City'].value_counts().to_dict()
data['Encoded_City'] = data['City'].map(frequency_encoding)
Output below:
Advantages of Frequency Encoding
Frequency encoding offers the following advantages:
It encodes categorical data in a straightforward and interpretable way, preserving the count information.
Particularly useful when the frequency of categories is a relevant feature for the problem you're solving.
It reduces dimensionality compared to one-hot encoding, which can be beneficial in high-cardinality scenarios.
When to Use Frequency Encoding
Frequency encoding is an appropriate choice when:
Analyzing categorical features where the frequency of each category is relevant information for your model.
Reducing the dimensionality of the dataset compared to one-hot encoding while preserving the information about category frequency.
Target Encoding or Mean Encoding
Target encoding, also known as Mean Encoding, is a powerful technique used to encode categorical features when the target variable is categorical.
It assigns a numerical value to each category based on the mean of the target variable within that category.
Target encoding is particularly useful in classification problems. It captures how likely each category is to result in the target variable taking a specific value.
How Target Encoding Works
The process of target encoding involves mapping each category to the mean of the target variable for data points within that category. This encoding method provides a direct relationship between the categorical feature and the target variable.
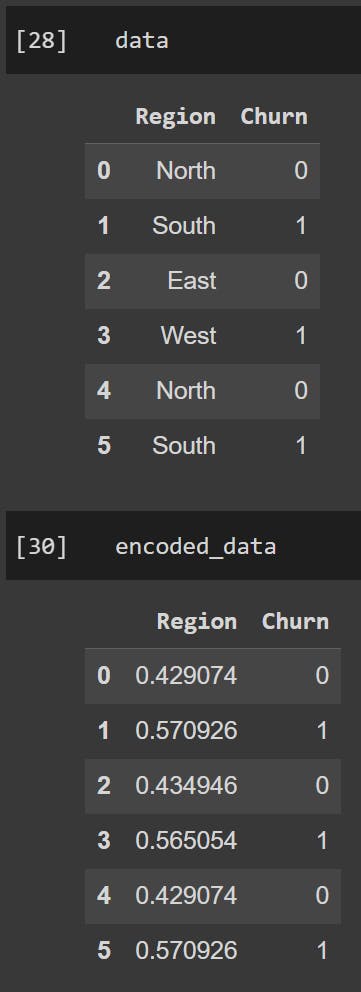
Consider a categorical feature "Region" with categories "North," "South," "East," and "West." If we're dealing with a binary classification problem where the target variable is "Churn" (0 for no churn, 1 for churn), target encoding might assign values as follows:
"North" → Mean of "Churn" for data points in the "North" category
"South" → Mean of "Churn" for data points in the "South" category
"East" → Mean of "Churn" for data points in the "East" category
"West" → Mean of "Churn" for data points in the "West" category
Code Implementation
Here's a Python code example for target encoding using the category_encoders library:
# imports
import category_encoders as ce
import pandas as pd
# Sample data
data = pd.DataFrame({'Region': ['North', 'South', 'East', 'West', 'North', 'South'],
'Churn': [0, 1, 0, 1, 0, 1]})
# Perform target encoding
encoder = ce.TargetEncoder(cols=['Region'])
encoded_data = encoder.fit_transform(data, data['Churn'])
Output is shared below:
Best Practices
When using target encoding, consider the following best practices:
Be cautious about potential data leakage, as the mean of the target variable is used in the encoding process. Ensure you're not using information from the test or validation set when encoding.
Use cross-validation or other techniques to prevent overfitting and improve the robustness of target encoding.
Advantages of Target Encoding
Target encoding offers several advantages:
It captures the relationship between the categorical feature and the target variable, making it useful in classification problems.
It provides a direct and interpretable way to encode categorical features.
It reduces dimensionality compared to one-hot encoding while preserving valuable information about category-specific behavior.
When to Use Target Encoding
Target encoding is an appropriate choice when:
Working with categorical features and a categorical target variable in classification problems.
You want to capture the relationship between the categorical feature and the target variable, helping the model make predictions based on category-specific behavior.
Feature Hashing or Hashing Trick
A rather under-appreciated encoding technique, Feature Hashing, also known as the Hashing Trick, is a method used to encode high-cardinality categorical features efficiently.
It works by applying a hash function to the categorical data, reducing the dimensionality of the feature while still providing a numerical representation.
💡 Feature hashing is particularly useful when dealing with large datasets with many unique categories.
How Feature Hashing Works
The feature hashing process involves applying a hash function to the categorical data, which maps each category to a fixed number of numerical columns.
The hash function distributes the categories across these columns, and each category contributes to the values of multiple columns.
Code Implementation
Let's implement this in Python.
import category_encoders as ce
import pandas as pd
# Sample data
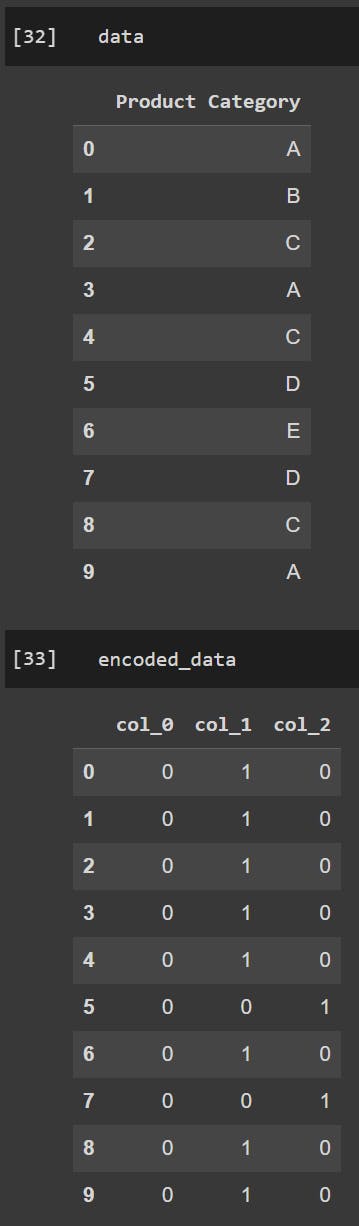
data = pd.DataFrame({'Product Category': ['A', 'B', 'C', 'A', 'C', 'D', 'E', 'D', 'C', 'A']})
# Perform feature hashing with three columns
encoder = ce.HashingEncoder(cols=['Product Category'], n_components=3)
encoded_data = encoder.fit_transform(data)
Output is shared below:
When to Use Feature Hashing
Feature hashing is an appropriate choice when:
Dealing with high-cardinality categorical features that have too many unique categories to handle using one-hot encoding or other techniques.
Reducing the dimensionality of the dataset while retaining the essential information from the categorical feature.
Memory and computational resources are limited, making it challenging to work with a high number of binary columns.
Define feature hashing.
Explain when to use feature hashing.
Provide code examples and implementation tips.
Discuss the impact of hash collisions.
Concluding thoughts
Here, we conclude the most useful encoding techniques for categorical variables for your data science and machine learning tasks.
Encoding data features is a crucial step in any machine learning pipeline and I hope that this article serves as a ready reference for all your upcoming projects.
Each technique has its strengths and is best suited for specific scenarios. Make sure to refer to the "When to Use" section for each encoding technique to apply the right feature encoding technique to your dataset.
The reference code is compiled for you in the notebook below.
Hope you enjoyed this!
Feel free to reach out for any queries or feedback below or on my socials.